
Scala vs. Python for Data Engineering: A Decision Framework
Most teams don't have a Scala problem or a Python problem. They have a layers problem. Someone picked a language for the whole stack when the right answer was different languages for different jobs, and now the data scientists are fighting the data engineers, and production pipelines are held together by convention instead of guarantees.
The Scala vs. Python question isn't really about language preference. It's about where in your architecture each one belongs. This post gives you the criteria to figure that out.
- Python owns ML model training. scikit-learn, TensorFlow, and PyTorch are Python-first. There is no Scala equivalent with comparable ecosystem depth.
- Scala owns large-scale data infrastructure. It is Apache Spark's native language and wins on type safety, distributed throughput, and production pipeline reliability.
- The question is not "Scala or Python". It's which language belongs at which layer of your stack.
- Mature data teams use both. Python for training. Scala for the pipelines that feed, clean, and serve data at scale.
- If your biggest problems are pipeline correctness and scale, Scala is worth the investment. If your biggest problems are model iteration speed, Python stays in front.
Scala vs. Python Is a Layer Decision, Not a Language War
Most Scala vs. Python debates stall because both sides are arguing about different layers of the same system.
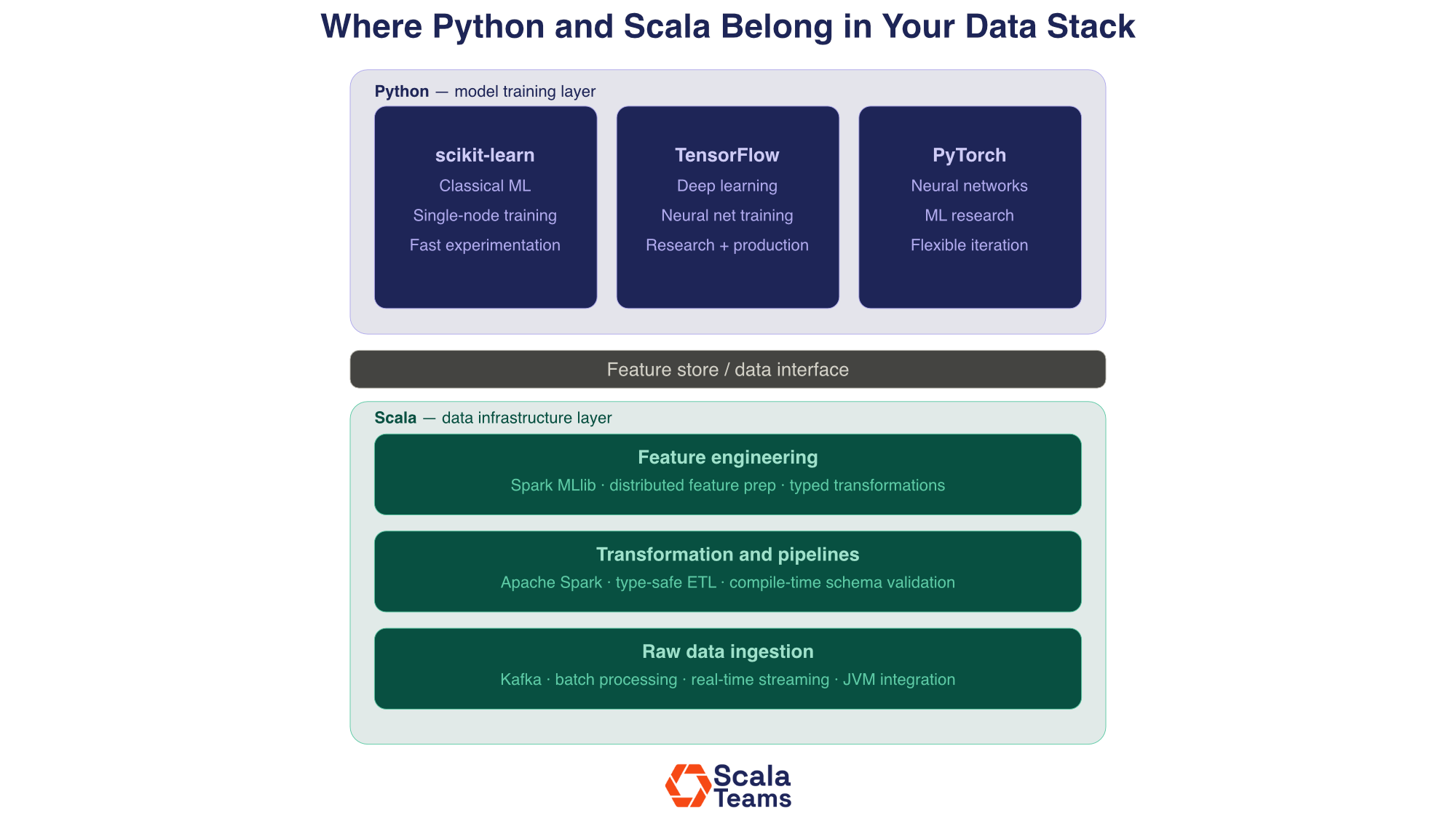
A data stack has at least three distinct layers. There is the data infrastructure layer: ingestion, transformation, and pipeline orchestration. There is the feature engineering layer: preparing and enriching data for modeling. And there is the model training layer: the actual fitting and evaluation of ML models.
Scala and Python have different strengths at each layer. Picking one as the universal answer means optimizing the wrong thing for at least part of your system.
The real question is: where is your current bottleneck, and which language's strengths map to it most directly?
Where Python Wins
Python didn't dominate data science by accident. scikit-learn, TensorFlow, and PyTorch are all Python-first, not because Python is the fastest language, but because the researchers who built those tools wrote Python, and the engineers who adopted them followed. The hiring pool, the Stack Overflow answers, the conference talks, the GitHub repos, all of it points in the same direction. When your data scientists sit down to train a model, they open a Jupyter notebook, and that's not changing.
ML Model Training
The ML tooling ecosystem lives in Python. scikit-learn, TensorFlow, and PyTorch are all Python-native. They have massive communities, years of documentation, and an active research presence. If your team is training models, they are using Python. That is not a preference; it is a structural reality of where the tooling exists.
Experimentation Speed
Jupyter notebooks and Python's REPL-style workflow are genuinely productive for exploration. Data scientists can iterate fast, test hypotheses, and share results without needing a full engineering setup. That speed matters in early-stage model development.
Hiring Data Scientists
The data science talent market is Python-first. If your team is primarily composed of data scientists rather than data engineers, Python reduces friction in hiring, onboarding, and day-to-day collaboration.
Where Scala Wins
The problems Scala solves best are the ones that don't show up until a system has been running for a year. A Python pipeline that works fine at launch starts showing its edges when the data volume triples, three engineers have touched the transformation logic, and nobody is quite sure what a column is supposed to contain anymore. Scala's type system forces those questions to be answered upfront, at compile time, before anything reaches production. That feels like friction early on. Later, it feels like the reason nothing is on fire.
Apache Spark Performance and Type Safety
Apache Spark is written in Scala. When you use PySpark, your code passes through a translation layer that adds overhead and removes compile-time type checking. In Scala, Spark jobs are statically typed: the compiler catches schema mismatches and transformation errors before anything runs.
On a small scale, this difference is manageable. Larger scale, with pipelines that process terabytes daily across dozens of transformation steps, a single uncaught type error in Python can surface as a production failure. In Scala, it surfaces as a compiler error before deployment.
// Scala Spark: schema errors caught at compile time case class UserEvent(userId: String, eventType: String, timestamp: Long) val events: Dataset[UserEvent] = spark.read .parquet("/data/events") .as[UserEvent] // This line fails to compile if 'userId' doesn't exist in the schema val filtered = events.filter(_.userId.nonEmpty)
# PySpark: schema errors surface at runtime events = spark.read.parquet("/data/events") # Typo in column name: no error until the job runs filtered = events.filter(events["user_id"] != "") # AnalysisException: Column 'user_id' not found (only at runtime)
Real-Time Streaming
Kafka is the dominant tool for real-time data streaming, and Scala integrates with it natively. For pipelines that need to process event streams at high throughput, like financial transactions, user activity, and sensor data, Scala's concurrency model and JVM performance are well matched to the workload.
Long-Term Pipeline Maintainability
Scala's functional programming approach enforces immutability and explicit data transformation. Over time, as pipeline complexity grows and team members turn over, this makes the codebase easier to reason about. Python data pipelines can accumulate mutable state and side effects that are hard to trace when something breaks at 2 a.m.
Scala vs. scikit-learn, TensorFlow, and PyTorch
Engineering leaders searching for this question usually have the same underlying concern: if we invest in Scala for our data infrastructure, are we giving something up on the ML side? It's a fair question. The short answer is no, but only because Scala and these libraries are not actually competing for the same job. Scala is not a replacement for your ML tooling. It's the layer underneath it. Understanding where each one sits in the stack is what makes the comparison useful.
Scala vs. scikit-learn
scikit-learn is a Python library for training classical ML models: regression, classification, clustering, and dimensionality reduction on single-node datasets. Scala has no equivalent at the same breadth. For this use case, Python wins without contest.
Where Scala enters the picture is in the data that feeds scikit-learn. If you are cleaning, transforming, and joining datasets that are too large for a single machine, Scala with Spark handles that preprocessing layer and outputs clean data that scikit-learn then trains on. The two tools are not competitors; they work at different points in the same workflow.
Spark MLlib, Scala's distributed ML library, is the relevant alternative when scikit-learn's single-node limit becomes a constraint. It supports distributed logistic regression, decision trees, and clustering, but its primary purpose is scale, not breadth of algorithm coverage.
Scala vs. TensorFlow
TensorFlow is Python-native for training. Scala cannot replace it for deep learning model development.
Scala's role in TensorFlow-based systems is in the surrounding infrastructure: building data pipelines that prepare training data, managing streaming systems that feed inference endpoints, and maintaining production services that serve model outputs. TensorFlow Serving can sit behind a Scala-based API layer that handles high-throughput prediction requests with the type safety and concurrency benefits the JVM provides.
Scala vs. PyTorch
Same answer as TensorFlow, with more emphasis on research flexibility. PyTorch is the dominant framework for ML research and experimentation. Scala has no competing tool for this purpose.
The practical question for engineering leaders is not "PyTorch or Scala?" It is: "Who maintains the infrastructure that PyTorch models depend on?" That infrastructure, feature pipelines, data ingestion, serving layers, is where Scala often makes more sense than Python, particularly at scale.
The Decision Framework
Every Scala vs. Python debate eventually comes down to specifics: your data volume, your team composition, your tolerance for production incidents. The generic answer "use the right tool for the job" is technically correct and completely useless. These five questions are designed to get past that. They won't decide for you, but they will surface the tradeoffs that actually matter for your situation.
1. What is the primary workload?
This is the most important question and usually the most clarifying. If the work is exploratory, like testing a hypothesis, fitting a model, or iterating on features, the feedback loop matters more than type safety, and Python wins on speed. If the work is operational, like moving data reliably, transforming it correctly, or delivering it on a schedule that other systems depend on, the stakes are different. Errors in production pipelines aren't inconvenient; they're incidents.
Experimentation, model training, notebook-driven research → Python
Production pipelines, data transformation, streaming at scale → Scala
2. What is your data volume?
Python works well until it doesn't, and the wall it hits is usually memory. Single-node processing has a ceiling. Once your data outgrows what one machine can hold, you need distributed computing, and that's where Scala's native Spark integration is a practical advantage. PySpark can get you there, but you're working against the grain of how Spark was designed.
GB-scale, single node → Python handles it fine
TB or PB-scale, distributed → Scala's Spark native advantage is material
3. Who owns the codebase?
This question is really about who gets paged when something breaks. Data scientists optimize for iteration speed; they need to move fast and change things often. Data engineers optimize for reliability and need code that holds up under conditions nobody anticipated when it was written. Those are different goals, and they tend to produce different preferences. Match the language to the person carrying the operational weight.
Data scientists who train and iterate on models → Python reduces friction
Data engineers who build and maintain production pipelines → Scala's type guarantees pay off over time
4. What are the production reliability requirements?
A failed research job means a data scientist reruns a notebook. A failed production pipeline means corrupted data, missed SLAs, and someone explaining to a compliance team what went wrong. The cost of a failure should inform the cost you're willing to pay upfront for correctness. Scala makes you pay that cost at compile time. Python defers it.
Research or internal tooling where failures are recoverable → Python's flexibility is fine
Customer-facing pipelines, financial data, regulated data flows → Scala's compile-time guarantees reduce incident risk
5. What does your existing stack look like?
Language decisions don't happen in isolation. Bringing Scala into a Python-first organization means new tooling, new build systems, and engineers who need to get up to speed. That's not a reason to avoid it, but it's a cost that should show up in your evaluation. If your organization already runs on the JVM, that cost drops significantly. Scala and Java share a runtime, which means existing infrastructure, libraries, and deployment patterns carry over.
Python microservices, Python-first team → Introducing Scala adds integration overhead; evaluate whether the tradeoff is worth it
JVM shop with Java services → Scala integrates without forcing a platform migration
The Architecture That Mature Data Teams Use
The most effective data organizations do not pick one language, they split by layer.
Scala handles data infrastructure: raw ingestion, large-scale cleaning and transformation via Spark, real-time streaming via Kafka, and the feature stores that feed downstream systems. Python handles the model training layer: data scientists work in Jupyter with scikit-learn, TensorFlow, or PyTorch, consuming features that the Scala pipelines prepared.
The interface between the two is usually a feature store, a data warehouse, or a set of well-defined data contracts. Scala writes to it. Python reads from it. Each team works in the language that matches their workload.
This split also simplifies the organizational question. Data engineers own Scala pipelines. Data scientists own Python models. Fewer territorial disputes, clearer ownership, and each layer optimized for its actual requirements.
How the Scala vs. Python Decision Affects Hiring
Scala engineers are harder to hire than Python generalists. That is a real constraint and worth factoring into your planning. The talent pool is smaller, interviews take longer, and compensation is typically higher.
What offsets that is productivity. Scala data engineers tend to be senior-level specialists. A smaller team of experienced Scala engineers can maintain pipelines that a larger Python team struggles with as complexity grows, partly because the type system enforces discipline that Python relies on convention to maintain.
Outsourcing or augmenting your Scala data engineering capacity sidesteps the hiring constraint entirely and lets your internal data scientists stay focused on the Python model layer. That is the path a growing number of teams are taking, particularly when Scala pipeline work is important but not the core competency they want to build in-house.
When to Choose Scala, When to Choose Python
The Scala vs. Python question resolves quickly once you stop treating it as a single binary choice. For the data layer, ask where your failures actually happen. If schema errors, pipeline corruption, and scaling bottlenecks are your recurring problems, the answer points toward Scala. If model iteration speed and data scientist productivity are the constraints, Python stays in front.
Most teams past a certain scale end up at the same answer: Python for training, Scala for infrastructure. Getting there deliberately is faster and cheaper than arriving at it after two years of accumulated pipeline debt.
We help engineering teams stand up and scale production Scala pipelines without the hiring headache. Talk to a Scala expert about what your stack needs.
Frequently Asked Questions
Should I use Scala or Python for data engineering?
For large-scale distributed pipelines, Scala is the stronger choice. It is Apache Spark's native language, provides compile-time type safety across complex transformation logic, and integrates cleanly with JVM-based infrastructure. Python is better for single-node experimentation, ML model training with scikit-learn, TensorFlow, or PyTorch, and teams whose primary staffing is data scientists. Most mature organizations use both: Python at the model training layer, Scala at the data infrastructure layer.
How does Scala compare to scikit-learn?
scikit-learn is a Python library for training classical ML models on single-node datasets. Scala has no equivalent at the same breadth. For single-node ML training, Python with scikit-learn is the clear choice. Scala is relevant in the preprocessing and pipeline layer that feeds scikit-learn models, large-scale feature computation, data cleaning at distributed scale, and productionizing data flows. Scala's Spark MLlib supports distributed ML training for cases where scikit-learn's single-node approach hits its limit.
Can Scala replace TensorFlow or PyTorch?
No. TensorFlow and PyTorch are Python-native deep learning frameworks. Scala has no equivalent with comparable adoption. If your team is training neural networks, they will use Python. Scala's value in AI workloads is in the surrounding infrastructure: the data pipelines that feed training jobs, the serving infrastructure that deploys models, and the streaming systems that process inference inputs at scale.
What is the difference between Scala and Python for machine learning?
Python dominates ML model training. The data science talent pool is built around it. Scala's role in machine learning is at the infrastructure level: building the data pipelines that feed ML systems, not training the models. Scala's distributed computing strengths via Apache Spark make it well-suited for large-scale feature engineering and data preparation, which is often the true bottleneck in production ML.
What is the hybrid Scala and Python architecture for data engineering?
In a hybrid Scala-Python data architecture, Scala handles ingestion, transformation, feature engineering via Spark, and real-time streaming via Kafka. Python handles model training using scikit-learn, TensorFlow, or PyTorch. The two layers connect at a feature store or data interface boundary. This lets each language do what it does best: Scala for correctness and scale at the pipeline layer, Python for the rich ML ecosystem at the training layer.